Motivation
I started this project a few months ago after seeing a couple of CppCon talks - specifically, the fantastic talks by Fedor Pikus on C++ atomics and Daniel Anderson on wait-free algorithms. This started as essentially a challenge to myself to fully implement a lock-free queue in C++, without looking at any existing solutions. I had never previously implemented a lock-free algorithm, so it seemed a good place to start. However, when after a good deal of work I came up with a working solution, I wanted to benchmark it compared to a few existing implementations and found it stacked up very favourably. This led me down a rabbit hole of experimenting with tricks to extract the maximum performance, the results of which I am sharing here. I should mention that I have no idea if similar solutions to mine already exist - I would imagine so, but I haven’t looked for them so who knows. Hopefully you may find one or two interesting tricks along the way though.
Background
We begin with some basics of lock-free programming. First, let us define what we mean by this.
Definition. A multi-threaded algorithm is called lock-free or non-blocking if the suspension of any thread or threads at any stage of the algorithm does not lead to other threads failing or being unable to proceed.
Another way of phrasing this is that provided at least one thread is running, then at all times at least one thread is making progress. A much stricter definition is the following:
Definition. A multi-threaded algorithm is called wait-free if, given a fixed number of threads , all threads are guaranteed to complete each operation in a bounded number of steps (depending on ).
This is obviously a subset of lock-free algorithms. Compared to the number of known lock-free algorithms, there are much fewer wait-free algorithms as most lock-free algorithms rely heavily on a process that could be loosely described as “guess what state the data is in, and if we are correct continue, else try again” - or more precisely, a compare-and-swap (CAS) loop - which is obviously not condusive to guaranteeing a bounded number of steps.
Definition An instruction is called atomic (coming from the greek word meaning “indivisible”) if, to an outsider (i.e. another thread), the instruction has either occurred, or it has not occurred. In other words, it is impossible for other threads to observe any intermediate state between the state before the instruction executes and after it has finished.
Note that many instructions are atomic by default on most modern architectures - such as reads and writes on integral types of width at most 8 bytes.
There are a relatively small number of atomic instructions on which almost all lock-free algorithms are built. We outline some of the fundamental ones:
- read: Read a value at a specified address
- write: Write a value to specified address
- exchange: Read a value at a specified address, and exchange it with another value
- compare-and-exchange or compare-and-swap (CAS): Read a value at a specified address and compare it to a given value expected. If it matches, store another given value desired, otherwise store the read value in expected
- fetch-some_operation: Read the value at a specified address and perform a binary operation to it with a given value, such as adding it to the value or performing a boolean operation with the value
The key to most lock-free algorithms lies in the CAS operation. This essentially allows us to perform a number of changes, and only “commit” them to our data structure if a certain condition is met.
For more background on lock-free programming, or if you want to learn about memory barriers, which we have not covered here, I would recommend you to check out the aforementioned videos.
Design
The core design of the queue consists of one non-atomic array of size to store the elements, and another array of atomic states to govern the access of the element array. On top of this, we have two atomic size_t types to keep track of the current front and back of the queue - this is just a counter that gets incremented each operation. To index array, we take this value modulo .
The state array stores two pieces of information. In the bottom two bits, we store the state of a given slot: EMPTY, FULL, READING or WRITING. The remaining bits are used as a cycle counter - each time we push an element to a new slot, this is incremented, so that on the first full pass over the array it will be 1, the second pass 2, and so on.
The main CAS loop is as follows. We describe for a push operation - pop is similar. First we load the current back counter, and do a CAS on the state array with expected value of an empty slot from last cycle, and a desired value of a full slot from this cycle.
From here, there are two main variants of the algorithm. The first is the true lock-free implementation:
If this fails, there are three possibilities: Firstly, another thread could be in the middle of a push, in which case the expected value would already be the desired value. Here, we do a CAS to help the other thread increment the back (preserving lock-free behaviour). Secondly, the queue could be full (if expected contains a non-empty slot from last cycle), in which case we may want to return false (in the case of try_push). Thirdly, the fail could be spurious (we use weak CAS as it is faster in testing). In any case, we return to the beginning of the main CAS loop.
When we have succeeded, we have reserved a state slot, and thus have exclusive write access to the current slot in the element array. We first increment the back with a CAS (another producer may have done it already for us). The we simply write to the slot in the element array and release it for reading by storing a full state from this cycle in the state array.
The second variant is something I tried whilst tuning the performance. Note that even in the case of no contention, the above algorithm has to do two (relatively expensive) CAS instructions. This is necessary to ensure our algorithm is lock free - if, say, a writer thread gets descheduled just after reserving a slot, but before incrementing the back, other threads must be able to help increment the back here to avoid blocking. However, in practise this example may be extremely unlikely, and better performance can be achieved by removing this second CAS. Instead, we remove the “helper” functionality in the CAS failure loop, and can thus do a cheaper atomic store operation to update the back after succesfully reserving a slot. This is a good example of the fact that in theory, lock-free or wait-free guarantees seem very nice - but this doesn’t necessarily transfer to real-world performance.
We should note here that technically (most) bounded queues are not truly lock-free, as if a thread stalled then eventually the queue would fill up and then block. However, in practise the same is true for unbounded queues as any real computer has a finite amount of memory! Therefore it is typical to take lock-free to really only mean up to a finite size.
Implementation and Optimisation Decisions
As a basic starting point, we put align the front and back indices to the cache line size to avoid contention between writing and reading threads. Furthermore, we restrict the size of the queue to a power of 2 so that all modulo operations are a simple bit shift.
The first idea I had to reduce contention when between concurrent threads was to step through the array in increments of the smallest odd step which ensures that addresses in the state array are on different cache lines. Note the use of an odd step guarantees full period modulo . We can see the impact this has in the below graphs. They show the average total time taken to push 1 million values through the queue one at a time (we do this by running two threads, one pushes to queue 1 then pops from queue 2, the other pushes from queue 2 then pops from queue 1), averaged over 500 runs:
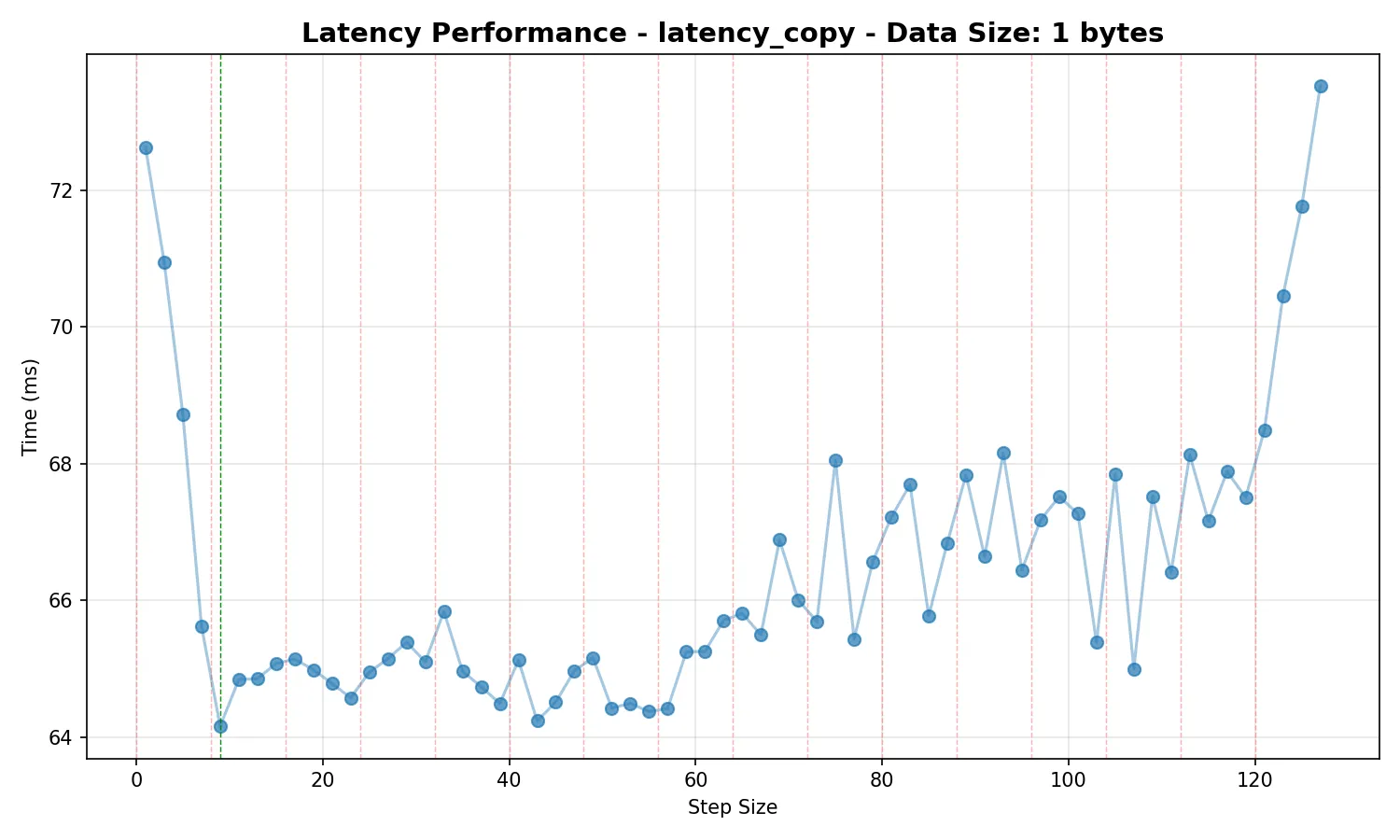
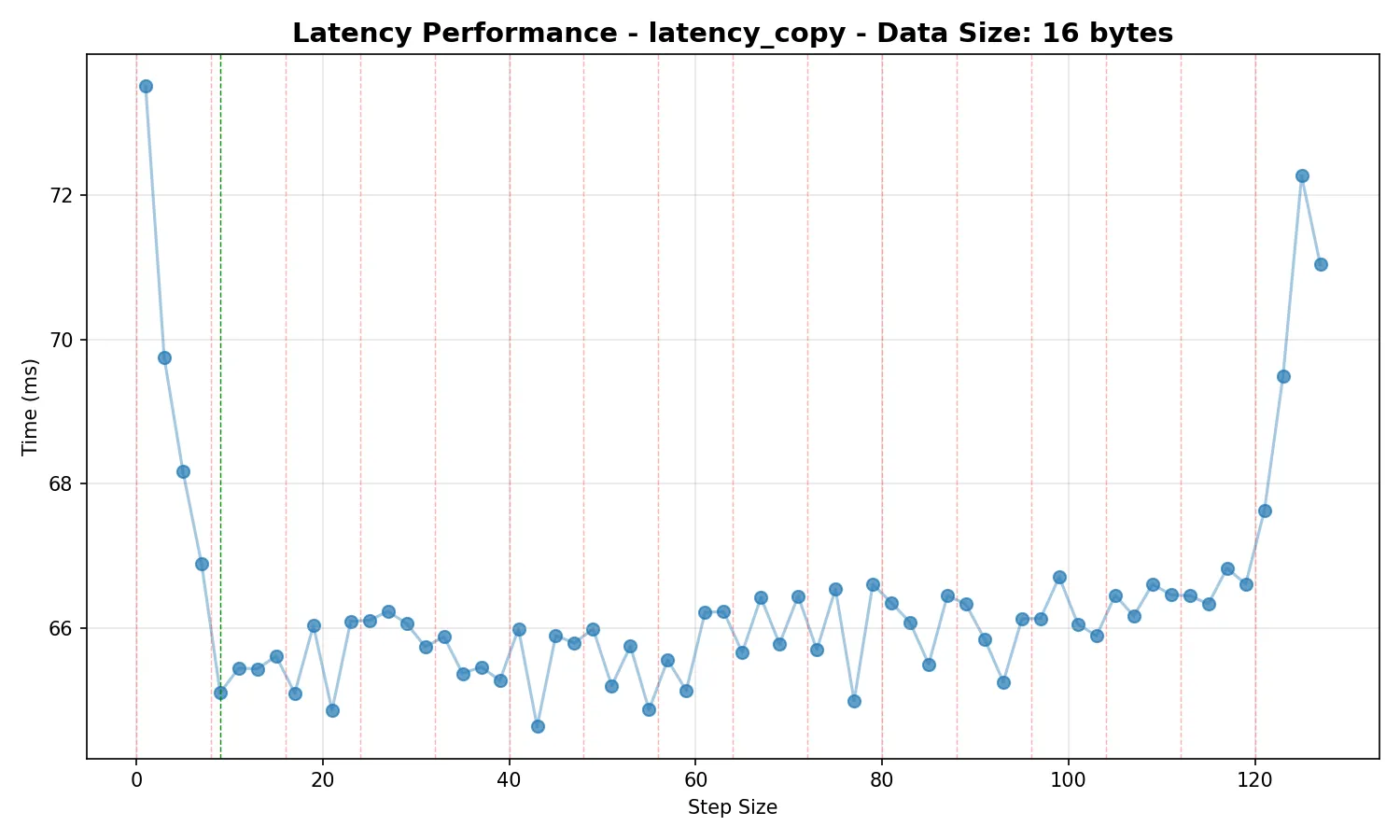
Note that the data size doesn’t matter here, as we would expect - we are not using any memory barriers when reading the actual elements, so there is no contention between threads accessing this memory.
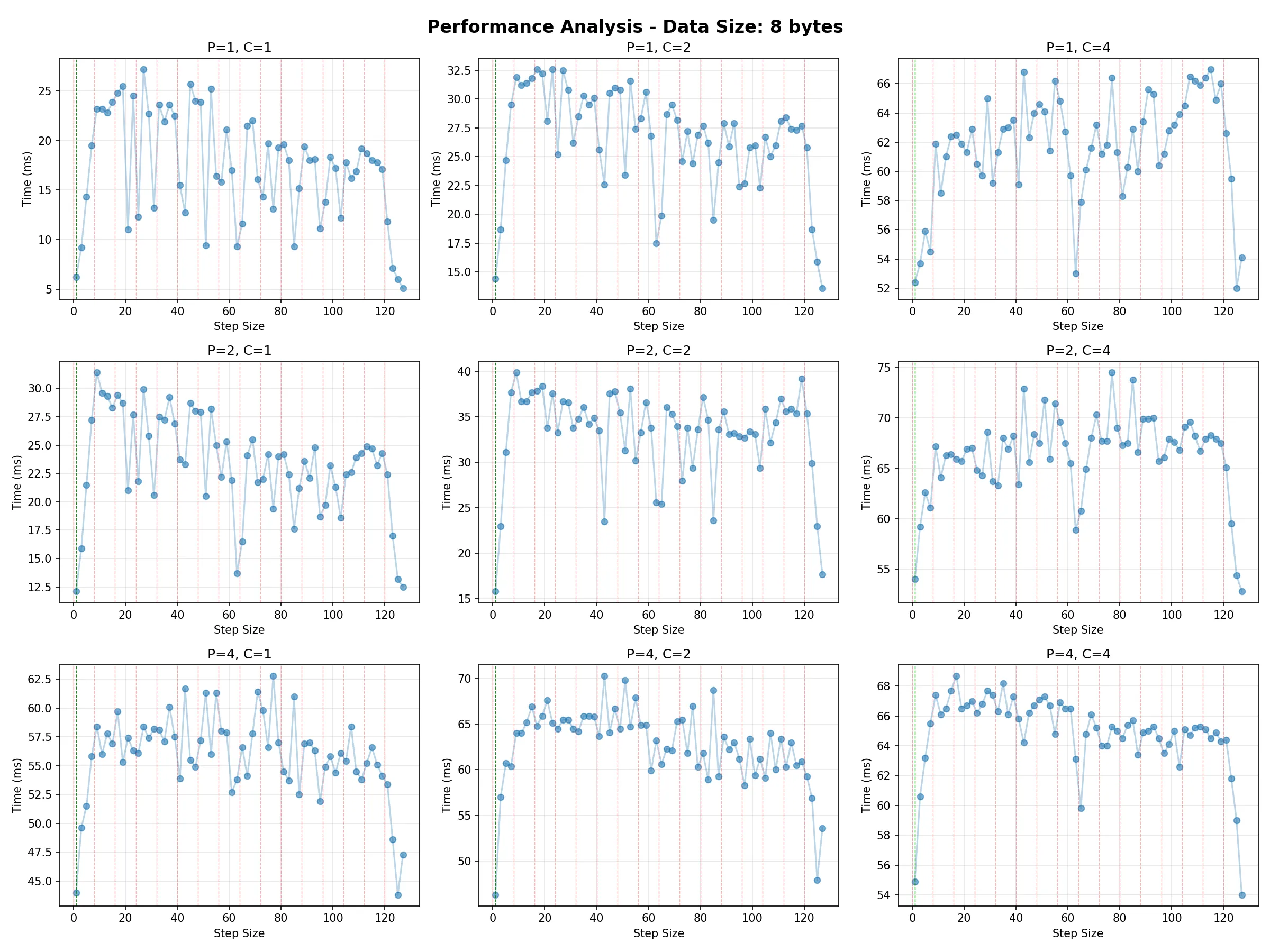
When optimising for throughput, we note that due to better locality for individual producer/consumer threads, it is better to use a step size of 1 and rely on slightly longer spin loop pauses to reduce contention (more on this below). The following graph shows the average total time taken to push 1 million total values through the queue with a variety of producer and consumer counts:
Next was to reduce contention in spin loops between competing threads. To do this, we have the PAUSE instruction on x86 and YIELD on ARM. I am less familiar with the ARM instruction, however the behaviour on x86 has several helpful properties. Firstly, it reduces contention on the desired cache line, which allows the other contending thread to write uninterrupted. Secondly, it prevents the CPU from speculatively pipelining instructions reading from this address as the spinning loop fails repeatedly - which would lead to a memory order violation and (expensive) pipline flush when the value at this address is written to from another thread. Thirdly, it allows more resources to be allocated to its SMT sibling.
Interestingly, even when optimising to minimise latency, it was found there were significant performance advantages to using more than one consecutive PAUSE instruction each time (at least on my test platform, a Ryzen 5600X where PAUSE is ~60 clock cycles or ~12ns). Unsurprisingly, the benefits were most extreme when optimising for throughput, when stacking a large number of pause instructions offers an enormous performance boost. This is essentially an effective method of “backing off” and allowing short (~1 microsecond) bursts of “SPSC-like” conditions for producers and consumers when hammering the queue.
Annoyingly, these instructions are VERY nonstandardised between platforms, with large variation in duration not just between AMD/Intel but also between different generations. For this reason we provide functions in test_latency.cpp and test_throughput.cpp which allow benchmarks to be run to determine the optimal values for your platform. Alternatively, it is relatively easy to check for a given x86 CPU how many cycles a PAUSE instruction occupies - we provide guidelines for choosing the correct parameters based on this as well, although if you want to get every last bit of performance it would be recommended to run the benchmarks as platforms may differ in other respects.
Solutions such as having a pause instruction in a for loop and reading the CPU TSC to count cycles proved to be significantly inferior in performance to just stacking plain PAUSE instructions - likely as methods like this introduce branching and require more resources which could be used by the hyperthread sibling. Furthermore, there are some recent instructions such as UMWAIT and TPAUSE, but the former was found to be extremely slow, and TPAUSE is not supported widely yet (I have not tested the performance as it is not available on my platform).
Benchmarks
We provide a selection of benchmarks to compare against existing implementations. All benchmarks were run on an AMD Ryzen 5600X. We show a few different configurations of our queue: Optimised for latency or throughput, and truly lock-free or the faster version described above. We colour our queue optimised for throughput in red, with the version optimised for latency in yellow. Note that the queues in grey are SPSC-only.
Latency
For this test, we take two queues, and in two threads repeatedly push to one queue and pop from the other. We push 100000 integers through the queue this way. This measures the average time taken for a value to be pushed and then popped from a queue - thus is a measure of latency.
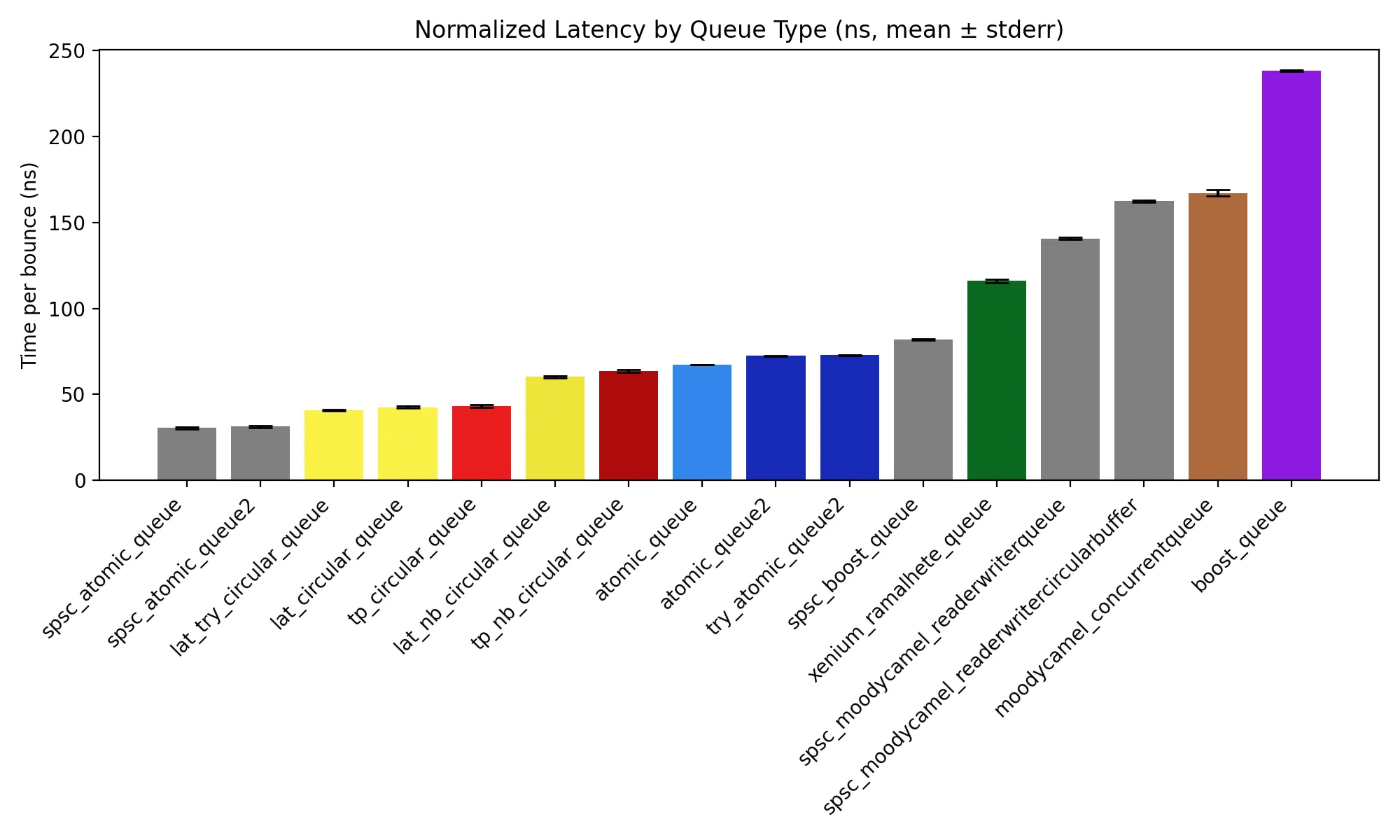
Throughput
Here, we simply push 1000000 integers through the queue for a varying number of producers and consumers, and measure the time taken.
Source code
I have released the queue as a single header-only library on my github under an MIT license.